What’s in a Namespace: The Critical Role of an Internal Concept Library for Scalable Pathology Data Management
Thursday May 28, 2026
Part one of a two-part series on the idea of Internal Concept Libraries

Modern pathology departments generate enormous volumes of clinically rich information every day. Yet much of that information remains effectively invisible to the systems used for identifying patients for research studies, biomarker-driven therapies, and clinical trials.
Much of the problem stems from a lack of structure.
Across healthcare institutions, pathology reports are still dominated by unstructured narrative text: highly expressive for human interpretation, but difficult for computers to interpret consistently. As precision medicine increasingly depends on identifying patients with highly specific molecular and histologic characteristics, this gap between human-readable and machine-readable pathology is becoming one of the most important bottlenecks in translational research. It prevents modern tools from leveraging critical data at scale.
At the 2026 Association for Pathology Informatics Summit, Raj Singh, Professor of Pathology at UPenn and PathPresenter co-founder, asked the audience to consider a clinical trial scenario: A researcher needs to identify patients with triple-negative breast cancer whose Ki-67 proliferation index exceeds 20%. Querying their institution’s database using the standard SNOMED CT concept associated with Ki-67 expression returns 47 patients.
The problem? The actual number of eligible patients in the database is 112.
Sixty-five patients were missed—not because the information was absent, but because it was described differently across pathology reports.
One report may say “Ki-67: 35%.” Another may describe “Proliferation index: 45%.” Others may reference “MIB-1 labeling index,” “Ki67 high,” or “Brisk mitotic activity.” To a pathologist, these phrases convey closely related clinical meaning. To a conventional search system relying on standardized terminology mapping, many are effectively invisible.

This challenge is not unique to Ki-67. It reflects a broader reality in pathology reporting.
Different institutions, and even different pathologists within the same institution, use varying terminology, abbreviations, units of measurement, and narrative styles. A tumor described as “2.2 cm” in one report may appear as “22 mm” in another and “0.022 m” in a third. Humans easily recognize these as equivalent observations. Most database search tools do not.
The industry’s primary solution to this problem has been terminology standardization frameworks such as SNOMED CT and the OMOP Common Data Model (CDM). These systems are essential foundations for interoperability and large-scale clinical research, and they are both impressive and commendable. But they also expose an important limitation: medicine evolves faster than standardized terminology systems can fully capture.
SNOMED CT (Systematized Nomenclature of Medicine Clinical Terms) is one of the world’s most comprehensive clinical vocabularies. It provides unique identifiers for clinical concepts so that systems across institutions can interpret observations consistently. When a pathology finding is successfully mapped to SNOMED, that information becomes interoperable and searchable across research networks.
OMOP CDM, meanwhile, provides a standardized database structure widely used by the OHDSI research community. OMOP enables federated research across hundreds of institutions while preserving patient privacy. Importantly, OMOP also supports custom local concepts through reserved concept ID namespaces. In other words, it explicitly leaves space in its system for concepts that haven’t been defined yet, knowing that medicine and research are always expanding.
Together, SNOMED and OMOP form the backbone of many modern clinical data infrastructures. But they are not sufficient on their own.
One core issue is that traditional pathology extraction pipelines often treat successful terminology mapping as a prerequisite for data preservation. If an extracted observation cannot be confidently mapped to a standard code, it is frequently discarded from downstream datasets entirely. Even if the data is preserved in local OMOP custom concepts, those local concepts do not provide any shared meaning across institutions.
This creates a dangerous form of silent data loss. The pathologist documented the finding correctly. AI extraction systems may even identify it correctly. But if no standard code exists, or if terminology matching fails, the information disappears from searchable research datasets.
For institutions engaged in clinical trials, biomarker research, or retrospective cohort studies, this means potentially eligible patients are never identified.
The solution proposed by Dr. Singh, in collaboration with Alexander Goel, COO at PhenoML, is the development of an Internal Concept Library. An internal concept is one stable name for one clinical observation: it gives a consistent way for people and systems to recognize it, regardless of how the pathologist wrote it. An Internal Concept Library acts as a canonical semantic layer between unstructured pathology language and external terminology systems.
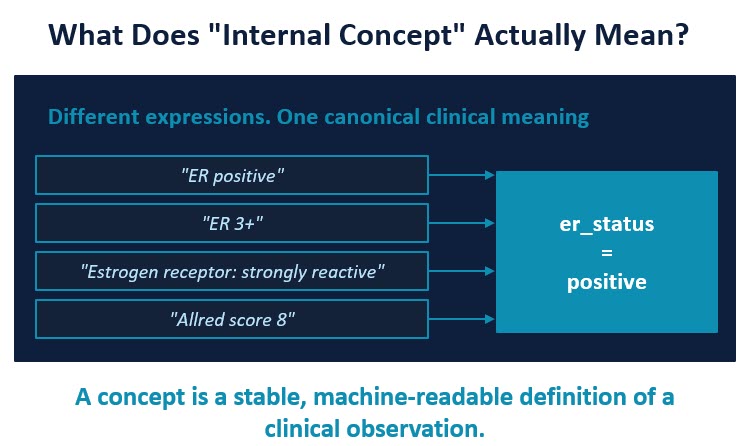
For example, multiple report expressions such as:
- “ER positive”
- “ER 3+”
- “Strongly reactive estrogen receptor”
- “Allred score 8”
can all resolve to a single internal concept:
er_status = positive
The internal concept becomes the persistent primary key. Standard terminology mappings are then attached downstream when available. Instead of treating SNOMED codes as the primary identifiers, this approach first maps observations to stable internal concepts designed specifically around clinical meaning.
This architectural distinction is critically important. If SNOMED mapping succeeds, the observation gains full interoperability. If SNOMED mapping fails, the observation is still preserved, queryable, and available for cohort discovery. Nothing is lost.

This approach also enables institutions to absorb local terminology variation across multiple sites and organizations to enable federated queries without constant schema redesign. New biomarkers, evolving grading systems, and emerging molecular concepts can be added incrementally to the concept library without restructuring the entire database architecture. New sites can be added to the collective queryable data network.
For pathology departments and institutional researchers, the implications are substantial.
An Internal Concept Library can improve cohort identification accuracy, preserve historically inaccessible clinical detail, support retrospective enrichment of older pathology archives, and create a more resilient foundation for AI-assisted research workflows.
Equally important, it aligns with how pathologists actually communicate clinically meaningful information. Pathologists have always preserved nuance for human readers. The challenge now is preserving that nuance for machines.
As precision oncology continues to advance, institutions that rely solely on rigid terminology (or no consistency at all) matching risk overlooking large portions of their own clinical knowledge base. The future of scalable pathology informatics may depend less on forcing every observation into a predefined standard, and more on building systems capable of preserving meaning first, then standardizing second.
The shift from code-first architecture to concept-first architecture may prove essential for the next generation of clinical research and patient discovery.
Part Two: Building a Library with AI
In the second part of this series, we’ll look at the design and results of a real-world project to build an internal concept library using a customized AI pipeline. Read Part Two: A Biomarker by Any Other Name Would Smell as Sweet: Building an AI-Powered Internal Concept Library
More Posts
- Expanding Access to Hantavirus Education: Sharing Images Through the PathPresenter Public Library
- The Future of Pathology Part 3: The Delivery Problem and the Infrastructure of Intelligence
- What ASCO Taught Me About the Future of Pathology – Part 2
- What ASCO Taught Me About the Future of Pathology
- A Biomarker by Any Other Name Would Smell as Sweet: Building an AI-Powered Internal Concept Library