A Biomarker by Any Other Name Would Smell as Sweet: Building an AI-Powered Internal Concept Library
Monday June 1, 2026
Part two of a two-part series on the idea of Internal Concept Libraries. Read part one.

The promise of artificial intelligence in pathology is often framed around image analysis and diagnostic augmentation. But one of the most immediate opportunities may lie elsewhere: transforming decades of unstructured pathology reports into computable, searchable clinical data.
A recent pathology informatics project by Raj Singh, Professor of Pathology at UPenn and PathPresenter co-founder, and Alexander Goel, COO at PhenoML, explored this challenge through the development of an AI-driven extraction pipeline designed around a central principle: preserve all clinically meaningful observations, even when standardized terminology systems fail to represent them completely.
The project focused on constructing an Internal Concept Library capable of bridging the gap between narrative pathology reporting and structured research databases.
The dataset consisted of 1,155 free-text pathology reports drawn from The Cancer Genome Atlas (TCGA), including breast, lung, and prostate cancer cases spanning 1978 to 2013. These reports largely predated modern synoptic reporting practices and therefore represented the type of highly variable narrative text still common throughout historical pathology archives.

The objective was not simply to extract data fields. It was to evaluate whether a concept-first architecture could preserve more clinically useful information than traditional terminology-dependent pipelines.
The system architecture was intentionally designed to separate clinical meaning from terminology standardization.
The pipeline began with ingestion of raw pathology reports. Cases were first routed through disease-specific classification using external terminology APIs and machine learning classifiers. Each report was then processed using large language model prompts tailored to individual disease sites.
Rather than allowing unconstrained extraction, the prompts used a closed-world design philosophy. The model was explicitly instructed that the field list was exhaustive, preventing the AI from hallucinating expected findings that were not actually documented in the report.
Each extracted observation was assigned an internal concept identifier before any attempt at external terminology mapping occurred. This architectural decision represented the core innovation of the project.
In traditional pipelines, extraction is often tightly coupled to successful SNOMED encoding. If no suitable standard code is found, the observation may be excluded from downstream datasets entirely.
In the concept-library model, however, the internal concept persists regardless of SNOMED availability.
Only after extraction were findings submitted to terminology matching systems to identify corresponding SNOMED CT or OMOP standard concepts. When no standard code existed, custom OMOP concept IDs were assigned instead, preserving full queryability within the OMOP ecosystem. The results highlighted the scale of the terminology gap.
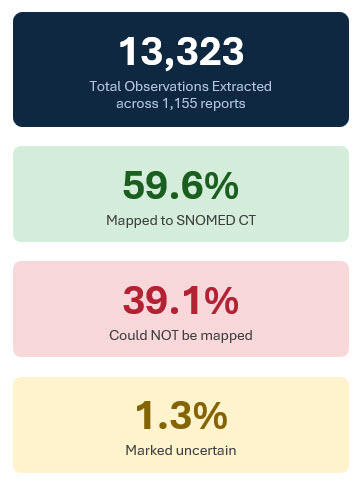
Across 1,155 reports, the system extracted 13,323 clinical observations. Of these, approximately 59.6% successfully mapped to SNOMED CT concepts. Roughly 39.1% could not be mapped to standard terminology despite representing clinically meaningful findings. An additional 1.3% were flagged as uncertain due to ambiguity or conflicting evidence within the report text.
Under conventional code-first architectures, a substantial portion of these observations would likely have been excluded from structured datasets entirely. Instead, the Internal Concept Library preserved all extracted findings.
The project also evaluated extraction completeness against the College of American Pathologists electronic Cancer Protocols (CAP eCPs), using the CAP templates as a formal benchmark for information coverage. This approach itself represented a novel methodological contribution, as CAP templates have rarely been used as explicit completeness standards in published large language model pathology extraction research.
Coverage varied by disease site. Breast reports achieved approximately 32.9% CAP field extraction, prostate reports 36.5%, and lung reports 21.8%, with an overall completeness rate of 29.2%.
At first glance, those percentages may appear modest. But the context matters enormously.
The TCGA reports originated from an era before structured synoptic reporting became widespread. Many CAP-defined fields simply did not exist within the source narratives. In other words, lower completeness often reflected absence of documentation rather than extraction failure.
The researchers hypothesized that applying the same pipeline to contemporary synoptic or semi-structured pathology reports would likely produce substantially higher completeness rates.
Several important design lessons emerged from the project.
- First, closed-world prompting proved essential. Explicitly constraining the extraction schema reduced over-extraction and prevented the model from inferring clinically plausible but undocumented findings.
- Second, the team found that self-reported LLM confidence scores were poorly calibrated and unreliable for quality assurance. Instead, better performance indicators emerged from structured assertion logic (e.g. forcing every extracted finding into explicit states such as present, absent, or uncertain rather than allowing vague narrative interpretation), explicit review of terminology concordance (verifying that extracted findings align consistently with accepted clinical vocabularies), and cross-field consistency checks (evaluating whether extracted observations remain clinically coherent when considered together).
- Third, the researchers intentionally avoided creating separate post-extraction normalization stages. Additional normalization layers often compound error propagation while duplicating functionality already present in terminology APIs.
Most importantly, the study demonstrated that pathology AI systems should prioritize preservation of meaning over immediate standardization.
This distinction has major implications for clinical trial recruitment and translational research. Using concept-level querying, researchers could identify highly specific patient cohorts using combinations of biomarkers, grading systems, and morphologic findings regardless of whether standardized terminology mappings existed for every observation.
Queries such as:
- Triple-negative breast cancers with Ki-67 greater than 50%
- Gleason score ≥8 with perineural invasion
could operate across the full extracted dataset, not merely the subset successfully encoded in SNOMED.
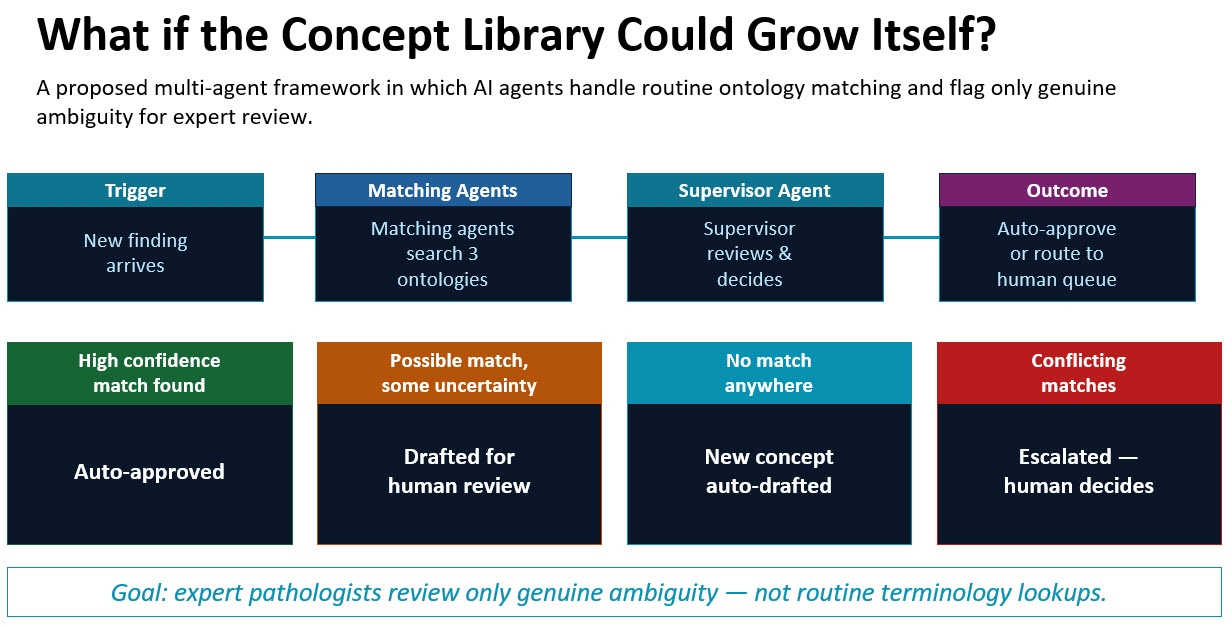
The project also pointed toward future directions in ontology management itself. Singh and Goel are considering multi-agent AI frameworks capable of automatically reviewing new observations, searching multiple ontologies, drafting candidate mappings, and escalating only genuinely ambiguous cases for human expert review. In such systems, pathologists and informaticians would spend less time performing repetitive terminology lookups and more time adjudicating clinically meaningful ambiguity.
Ultimately, the work reinforces a broader shift occurring across healthcare AI. The goal is no longer simply extracting structured data from pathology reports. The larger challenge is preserving clinical meaning at scale while enabling interoperability, research, and machine reasoning.
Pathologists have always documented nuanced clinical interpretation for human readers. Building systems that preserve that same nuance for computational systems may become one of the defining informatics challenges of precision medicine.
More Posts
- Expanding Access to Hantavirus Education: Sharing Images Through the PathPresenter Public Library
- The Future of Pathology Part 3: The Delivery Problem and the Infrastructure of Intelligence
- What ASCO Taught Me About the Future of Pathology – Part 2
- What ASCO Taught Me About the Future of Pathology
- A Biomarker by Any Other Name Would Smell as Sweet: Building an AI-Powered Internal Concept Library